


Apart from coordinating BiCIKL, scholarly publisher and technology provider Pensoft has been the engine behind what is likely to be the first production-stage semantic system to run on top of a reasonably-sized biodiversity knowledge graph.
OpenBiodiv is a biodiversity database containing knowledge extracted from scientific literature, built as an Open Biodiversity Knowledge Management System.
As of February 2023, OpenBiodiv contains 36,308 processed articles; 69,596 taxon treatments; 1,131 institutions; 460,475 taxon names; 87,876 sequences; 247,023 bibliographic references; 341,594 author names; and 2,770,357 article sections and subsections.
In fact, OpenBiodiv is a whole ecosystem comprising tools and services that enable biodiversity data to be extracted from the text of biodiversity articles published in data-minable XML format, as in the journals published by Pensoft (e.g. ZooKeys, PhytoKeys, MycoKeys, Biodiversity Data Journal), and other taxonomic treatments - available from Plazi and Plazi’s specialised extraction workflow - into Linked Open Data.
“I believe that OpenBiodiv is a good real-life example of how the outputs and efforts of a research project may and should outlive the duration of the project itself,” explains Prof Lyubomir Penev, BiCIKL's Project Coordinator and founder and CEO of Pensoft. “Something that is - of course - central to our mission at BiCIKL.”
“The basics of what was to become the OpenBiodiv database began to come together back in 2015 within the EU-funded BIG4 PhD project of Victor Senderov, later succeeded by another PhD project by Mariya Dimitrova within IGNITE. It was during those two projects that the backend Ontology-O, the first versions of RDF converters and the basic website functionalities were created,” he adds.
At the time OpenBiodiv became one of the nine research infrastructures within BiCIKL tasked with the provision of virtual access to open FAIR data, tools and services, it had already evolved into a RDF-based biodiversity knowledge graph, equipped with a fully automated extraction and indexing workflow and user apps.
Currently, Pensoft is working at full speed on new user apps in OpenBiodiv, as the team is continuously bringing into play invaluable feedback and recommendation from end-users and partners at BiCIKL.
As a result, OpenBiodiv is already capable of answering open-ended queries based on the available data. To do this, OpenBiodiv discovers ‘hidden’ links between data classes, i.e. taxon names, taxon treatments, specimens, sequences, persons/authors and collections/institutions.
Thus, the system generates new knowledge about taxa, scientific articles and their subsections, the examined materials and their metadata, localities and sequences, amongst others. Additionally, it is able to return the information with a relevant visual representation about any one or a combination of those major data classes within a certain scope and semantic context.
Users can explore the database by either typing in any term (even if misspelt!) in the search engine available from the OpenBiodiv homepage; or integrating an Application Programming Interface (API); as well as by using SPARQL queries.
On the OpenBiodiv website, there is also a list of predefined SPARQL queries, which is continuously being expanded.
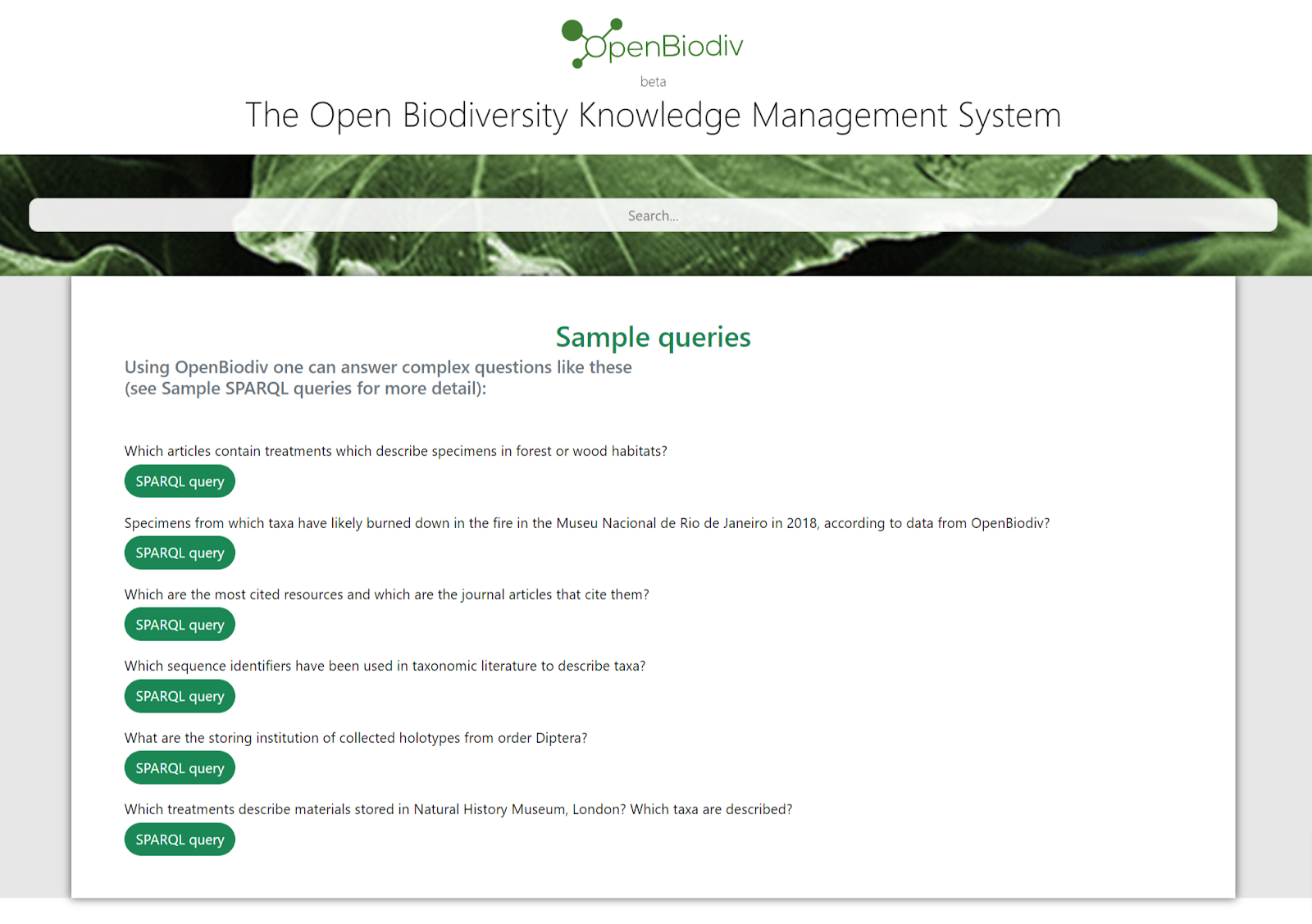
Sample of predefined SPARQL queries at OpenBiodiv.
“OpenBiodiv is an ambitious project of ours, and it’s surely one close to Pensoft’s heart, given our decades-long dedication to biodiversity science and knowledge sharing. Our previous fruitful partnerships with Plazi, BIG4 and IGNITE, as well as the current exciting and inspirational network of BiCIKL are wonderful examples of how far we can go with the right collaborators,” concludes Prof Lyubomir Penev.
***
Follow BiCIKL on Twitter and Facebook. Join the conversation on Twitter at #BiCIKL_H2020.
You can also follow Pensoft on Twitter, Facebook and Linkedin and use #OpenBiodiv on Twitter. Interoperable biodiversity data extracted from literature through open-ended queries: The OpenBiodiv contribution to BiCIKL